Gemini APIで自作ペンプロッタにフィジカルAIを搭載してみた
2026/02/22
こんにちは。株式会社HIBARIの眞邉です。
PCや家電など、何にでもAIが搭載される時代になりました。そこで本記事では、押し入れに眠っていた自作ペンプロッタにAIを搭載することに挑戦してみました。
Gemini APIを利用してかんたんに実装することができましたので、フィジカルAI入門の実装例として是非ご一読ください。
背景
昨年12月、初めて国際ロボット展(iREX)を観てきました。様々な種類のロボットがある中で、特にファナック・NVIDIAが展示をしていた自然言語で操作できるロボット、いわゆるフィジカルAIの展示が印象的でした。
自分でも作ってみたいと思い画策していたところ、過去に趣味で製作したペンプロッタの存在を思い出しました。これなら金欠な私でも手軽に試すことができそうです。
そこで、このペンプロッタを使用して簡単なフィジカルAIを製作してみることにしました。
手法
手軽な実装を目的とするため、諸々の推論はすべてGeminiに任せることとしました。
Gemini APIに次のデータを投げます。
・ システムプロンプト
・ プロンプト
・キャンバス画像
Gemini APIからロボットの操作シーケンスをJSONで返してもらいます。
シーケンスをエッジで解析し、Geminiの返答をTTSしながらペンプロッタを制御します。
・本当はプロンプトを音声で投げたかったのですが、環境の都合上テキスト入力により行うこととしました。
実装
ペンプロッタの整備
昔製作したペンプロッタはArduinoMega専用に設計したPCBを使用しています。

もう少し高速化させつつ、WiFiに対応させたいのでESP32にリプレイスしました。
奥で配線がスパゲッティみたいになっているのは、Arduino用のシールドを無理矢理ESP32の開発ボードに接続しているためです...
制御にはFluidNCを使用しました。
ピン配置等、マシンのメタデータとなる情報をyamlで記述するだけですぐに動作確認ができました。すごく便利。
エッジとなるPCからTelnetでLANを経由してGcodeを送信することで制御します。
キャンバスの画像をGeminiAPIに送信する必要があるので、カメラもつけておきます。

プログラムの実装
大まかなフローを下図に示します。
主要な動作について、詳細を後述します。

座標変換
カメラで撮影した画像をそのままGeminiに送信すると、
カメラの傾き
直角出しがいい加減な自作ペンプロッタの歪み
などの要因により「Geminiが『ここ!』と指し示した点」と「プログラムがペンプロッタに移動させる点」との間に錯誤が生じます。
そこで、ホモグラフィ変換による補正を実装しています。ホモグラフィ変換については下記リンクを参照してください。
https://qiita.com/naosk8/items/cde89dd93044e0abb054
1.最初に、ペンプロッタの可動域四隅に点を描画させます。

2.プログラムは、ユーザにこれらの点の位置を知らせるよう促します。見づらいですが、緑色の+をキーボードで操作することで調整します。

3.入力が完了すると、ホモグラフィ変換の変換行列が生成され、描画領域の像を確認することができました。

GeminiAPIおよびCloud TTSとの通信
本プログラムは、PythonでGemini APIを叩くことでGeminiからのレスポンスを取得します。
Gemini APIは音声によるレスポンスを取得することができます。しかし、今回の用途では音声だけでなく制御シーケンスにまつわる様々な情報も含めたいため、一度すべてテキスト(JSON)で返答させることとしました。発声させたいテキストは再度Cloud TTS APIに投げることで音声として取得します。
詳細な手順は解説記事がたくさんあるため省略しますが、ざっくり分けると次の手順で実装します。
Google cloud consoleでAPIキーを発行する
・このとき、APIキーがGemini APIとCloud Text-to-Speechの両方を叩けるようにしておきます。
Pythonとgoogle公式のライブラリを使用し、APIキーとともにリクエストを送信するロジックを実装
・Gemini APIの使用には
google-generativeaiライブラリを使用します。・Cloud TTS APIの使用には
google-cloud-texttospeechライブラリを使用します。
システムプロンプトの実装
音声を再生しながらペンプロッタを制御するため、Geminiには次に示す情報を返してほしいです。
発声したいテキスト
描画したい図形情報
発声および描画の順番、タイミング
そこで、システムプロンプトに次に示すスキーマで返答をするよう記述しました。
このように、Geminiには「発声」「プロッタで直線を描画」の2つのアクションが許可され、これらをシーケンシャルに組み合わせたJSONで返答をさせます。
下部に記述されている返答例は、回路図に注釈を書き加えながら誤りを指摘する例です。blocking属性によって、動作が非同期的に行われるか、同期的に行われるかを指定することができます。これにより、書きながら話す動作を実現しました。
// 次のアクションは発声か、描画か
type ActionType = "speak" | "draw";
// 描画アクションで直線の始点終点を指定する
interface line {
x1: number;
y1: number;
x2: number;
y2: number;
}
// アクションを記述するためのインターフェイス
interface Action {
action: ActionType;
blocking: boolean; // この動作が完了するまで次の動作を待機するか
}
interface SpeakAction extends Action {
content: string; // TTSで読み上げるテキスト(記号はカタカナ表記)
}
interface DrawAction extends Action {
lines: line[]; // 描画する直線郡
}
// 返答形式
type ResponseJson = (SpeakAction | DrawAction)[];
// -------------------- 返答例 --------------------
const example: ResponseJson =
[
{
"action": "speak",
"blocking": true,
"content": "この回路図は概ね正しいですが、一点だけ修正が必要です。"
},
{
"action": "speak",
"blocking": false,
"content": "この部分の配線は、"
},
{
// 四角形で囲う例
"action": "draw",
"blocking": true,
"lines": [
{"x1": 316, "y1": 391, "x2": 404, "y2": 391},
{"x1": 404, "y1": 391, "x2": 404, "y2": 460},
{"x1": 400, "y1": 460, "x2": 316, "y2": 460},
{"x1": 316, "y1": 460, "x2": 316, "y2": 391}
]
},
{
"action": "speak",
"blocking": true,
"content": "繋がっていてはいけません。ショートする可能性があります。"
}
];(余談)描画する図形の表現方法について
今回、Geminiには直線のみの描画を許可しました。
実装当初はsvgを返答させることで自由度の高い描画をさせていたのですが、これをすると空間認識能力が大幅に低下し、全く関係のない場所に図形やテキストを配置するようになってしまい、断念しました。
プロンプトの詰めが甘かったのかもしれませんが、今回は直線の始点終点を正規化座標で指定させる方式で妥協しました。
実際に動作させてみる
実装が終わったので、いくつかのシチュエーションで動作確認をしました。
物体認識
いくつかの素敵なイラストが描いてある状態で、「どこにどんな絵があるか教えて」と頼みました。

(音声を載せられていませんが、PCのスピーカーから字幕のとおりに発声しながら描画されています。)

余すことなく、はみ出すことなく、絵を囲いながら説明してくれました。
次に、私がかっこいいハサミのイラストを描き加えて再度説明をしてもらいます。

ハサミを認識して囲んでくれましたが、既に囲み終わっている車のイラストを新しいイラストと認識し、二重に印をつけてしまいました。
回路レビュー
次に、かんたんな回路レビューを頼んでみました。
ベース抵抗が欠損しており、過電流が流れてしまう欠点をもつ回路図を見せ、「この回路でLEDを点灯させようとしたらすごいことになってしまいました。なぜ、すごいことになってしまったのか、どうすればよいのか、説明してください」と頼みました。

(原点からペンを引きずってしまっていますが、ペンプロッタの制御プログラムの不具合です。)
原因を特定して、抵抗を追加してくれました。
少し物足りないので、回路図を清書させてみます。「空いているスペースに回路図を清書してください」と頼みました。

正しい回路を清書してくれましたが、配線が欠けていたり、はみ出してしまいました。
直線の座標のみを出力させているため、表現力に対して要求がハードすぎたかもしれません。
論理回路設計
回路つながりで、更にハードルを上げてみます。
「JK-FFを使用した非同期式4進カウンタとそのタイミングチャートを描いて」と頼みました。曲線を描くことはできないので、直線で表現できない部分は省略して良い、と付け加えています。

(データ容量の都合上、発声部分をカットしたり2倍速にしたりしています。)
ラベルがない(描けない)のでなんとも言えませんが、構成としては間違っていません。
やっていること自体は間違っていないため、よりクォリティを上げるにはやはり表現力を高める必要がありそうです。
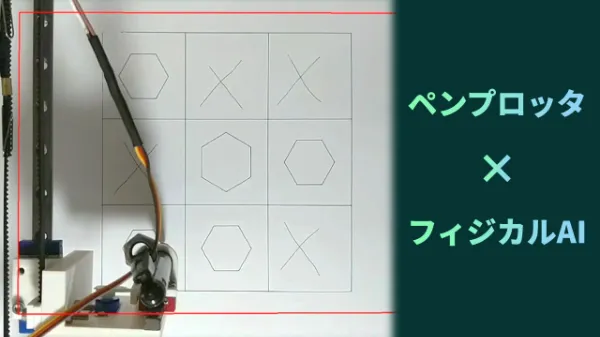
マルバツゲーム
最後に、インタラクティブなことに挑戦してみます。
「マルバツゲームをしましょう。まずはグリッドを書いて」と頼みました。
最初にグリッドを描いてくれましたので、私は手描きでバツをつけました。
以後、バツを描くたびに「書きました、どうぞ」と送信します。
やり取りを何度か繰り返すことで、ルールを守りながらゲームを完了し、引き分けにすることができました。

(データ容量の都合上、発声部分をカットしたり6倍速にしたりしています。)
Geminiの空間認識について
いくつかのシチュエーションを実際に試してみましたが、概ね正しく動作することを確認できました。
一方で、表現力に関する課題が浮き彫りになりました。
前述したように、今回はGeminiに直線の描画のみを許可しましたが、これには理由があります。
当初はsvg形式で描画したいものを出力させていたのですが、svgを生成させると途端に空間人意識能力・精度が低下してしまいました。
グリッドを追加してみたり、空間認識に関するルールや補助をプロンプトに追記してみたり、試行錯誤してみましたがsvg上での座標管理がうまくできていないようでした。

(赤線はエッジで描画した補助グリッド、緑線はGeminiが描画しようとした図形)
LLMが認識しやすいデータ形式(json,md,csv等)について様々なところで議論が起こっていますが、ベクタ形式の画像についても同様のことが言えそうです。
あくまで私の環境、プロンプトでの話ですが、うまく行った手法、効果を感じられなかった手法をまとめていきます。
効果がなかったこと
グリッド(補助線)の追加
入力画像の上に、軸を10等分する赤線を引きました
悪影響はありませんでしたが、効果もありませんでした
svg形式による描画
テキストや円弧を許可したsvgを描画させてみましたが、相対位置よりも絶対的な位置関係の認識が苦手な傾向がありました
プロンプトでキレる
「厳格に」「精密に」「入力画像と位置関係がズレてはいけない」など、プロンプトで強調を加えることは全く効果がありませんでした。
効果があったこと
ホモグラフィ変換
当然ですが、プロッタが見ている座標系とAIが見ている座標系は統一したほうがよいです。
しかし、AIが見れるのはカメラを経由した空間のみなので、歪みを補正してあげる必要がありました。
AIの空間認識能力というよりも、AIの出力が現実に反映されるときの精度が劇的に向上します。
グレースケール化
今回は白い紙に黒いペンで描画をするだけだったので、実装途中で入力画像をグレースケールに変更しました。
スマホのカメラで撮影をしていたため、照明の当たり具合によって余計な色補正が入っており、ノイズになっていたようです。
入力画像の規格化
実装当初は、カメラの画像をホモグラフィ変換したものを直接入力していました。
しかし、これでは、キャリブレーションを実行するたびにアスペクト比が変化します。
座標は0-1000に正規化させていたので問題はありませんでしたが、AIからすると問題だったようです。
画像に白でベタ塗りした帯(余白)を加えることで、入力画像が常に1:1になるように変更を加えたところ、座標ズレがかなり改善されました。
まとめと展望
今回、フィジカルAIに入門するべく、押入れに眠っていたペンプロッタにAIを載せてみました。
自前のLLMモデルでなく、高性能なGeminiを使用したためタスクを正確に認識し、所望の動作を的確に実現してくれた一方で、その表現力に関する課題が浮き上がりました。
特に、入力形式および出力形式によって空間認識能力が大きく変化することは初めて知ったことでした。
複雑な回路図や機械図面を人間とプロッタが一緒にかけるようになることを目標としているので、まだまだ表現力が足りていません。
svgに変わる独自の形式で図形を記述させるなど、アイデアはまだまだたくさんあるのでいろいろ試していきます。進展があればまた記事にしようと思っています。

株式会社HIBARI
株式会社HIBARIは、「”現場の抱える課題”をデジタルツイン×AIで解決する」をミッションに掲げる、沼津高専発のAIスタートアップです。静岡県を拠点に、テクノロジーを駆使しながらも現場に寄り添った「ものづくり」を発信しています。
\ 現在、エンジニアメンバーを募集中です! /
AI開発やシステム導入に関するご相談など、お気軽にお問い合わせください。
Contact